1. 풀링 계층 (Pooling Layer)
CNN에서 Pooling은 특징을 뽑아내는 역할을 수행한다. Pooling 이전의 과정을 살펴보면, 입력된 이미지가 convolution연산을 거치고, Activation function을 통과시켜 ReLu 연산을 통해 한 번 더 정리해주는 작업이 진행된다. 그렇게 생성된 이미지는(output feature map) 풀링 계층에 입력된다.


2. Pooling 연산의 종류
아래 그림은 스트라이드가 2로 설정된 풀링 계층의 동작 방식이다. 이를 통해 Max Pooling과 Average Pooling에 대해 알아보자.
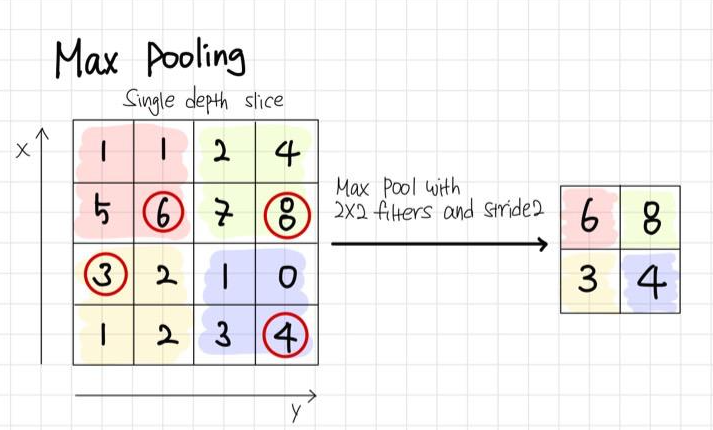
2-1. Max Pooling
Max Pooling 연산 방법은 가장 큰 값을 해당 영역의 대푯값으로 설정하는 것이다.
그리고 Max Pooling은 이미지의 중요한 정보를 뽑아서 이미지 사이즈를 4X4에서 2X2로 줄여나가기 때문에 Sub Sampling이라고도 불린다.
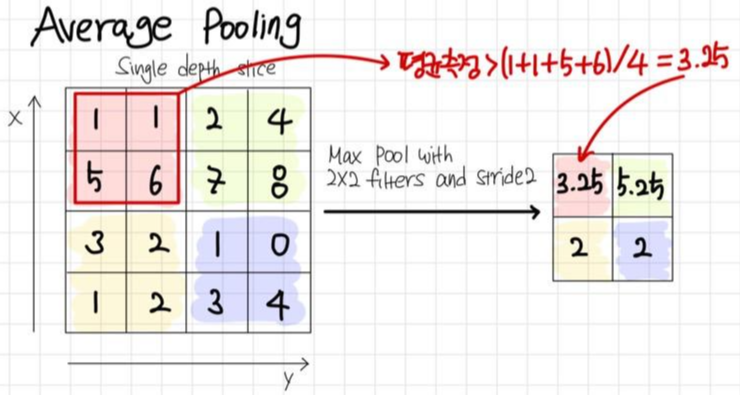
2-2. Average Pooling
Average Pooling 연산 방법은 해당 영역의 평균을 대푯값으로 설정하는 것이다.
정리하자면 Pooling 계층은 크게 Max Pooling과 Average Pooling으로 나뉘어지고, 일반적으로 Max Pooling을 더 많이 사용한다. 그 이유로는 filter 통과해 나온 결과인 feature map 위의 숫자들 중 특징에 가까우면 가까울수록 큰 숫자가 나오기 때문이다.
3. 실습코드
3-1. Pooling 실습코드


왼쪽은 Padding이 없는 코드이고 오른쪽은 Padding이 적용된 코드이다. 왼쪽의 경우, 출력값이 가장 큰 값인 4가 되는 것을 확인할 수 있고, 오른쪽 코드를 보면 해당 영역에서 가장 큰 값인 4,3,2,1이 출력되는 것을 확인할 수 있다.
3-2. Convolution Layer와 Pooling Layer 연결 실습코드

MNIST Dataset을 이용해 Convolution Layer와 Pooling Layer를 쌓는 실습코드를 살펴보도록 하자.


먼저, Convolution Layer 실습코드를 살펴보자.
3X3 사이즈를 가진 5개의 필터로 연산을 수행하고, 스트라이드는 2, 패딩은 적용하고 있다.
28X28 사이즈의 이미지가 14X14 사이즈로 출력된 것을 확인할 수 있다.
다음으로 Pooling Layer 실습코드를 살펴보자.
풀링 2X2 사이즈로 설정하고 스트라이드는 2, 패딩은 적용하고 있다.
앞서 입력으로 들어온 14X14 사이즈의 이미지가 7X7 사이즈로 출력된 것을 확인할 수 있다.
4. Summary

CNN은 Convolution Layer와 Pooling Layer을 통해서 특징을 뽑아내고 마지막에 Fully-connected Layer을 통해 실제 Classification을 하는 것이다.
위 그림은 실제 필터를 보여준 것이다. 이미지에 가까운 쪽 레이어에서는 단순한 형태의 feature들을 뽑아내게 되고 중간 정도의 레이어에서는 조금 더 복잡한 형태의 feature들을 뽑게 된다. 맨 마지막 레이어에서는 더 복잡한 high-level의 feature들을 뽑게 된다. 마지막으로 fully-connected 레이어에서 feature들을 모아 최종 classification을 하는 순서로 동작한다.
'Study > AI' 카테고리의 다른 글
| [머신러닝/딥러닝] Language Modeling 1 (언어모델) (0) | 2021.10.11 |
|---|---|
| [머신러닝/딥러닝] 이미지 어그멘테이션 (Image Augmentation) (0) | 2021.08.03 |
| [머신러닝/딥러닝] GAN 요약 정리 (0) | 2021.07.13 |
| [머신러닝/딥러닝] 합성곱 신경망(Convolutional Neural Network , CNN) (0) | 2021.05.17 |
| [모두를 위한 딥러닝 시즌2] Machine Learning의 용어와 개념 (0) | 2021.04.12 |



