언어모델(Language Model, LM)
- 단어 시퀀스(또는 문장)에 확률을 할당하는 모델
- 문장 자체의 출현 확률 예측 or 이전 단어들이 주어졌을 때 다음 단어를 예측하기 위한 모델
- 단어와 단어 사이의 출현 빈도를 세어 확률을 계산한다.
- 언어의 문장 분포를 정확하게 모델링하는 것이 목표이다.
- 음성인식, 번역모델 등 다양한 곳에서 사용한다.
언어모델 수식

주어진 코퍼스 문장들의 likehood를 최대하 하는 파라미터를 찾아내,
주어진 코퍼스를 기반으로 언어의 분포를 학습한다.
(코퍼스 기반으로 문장들에 대한 확률 분포 함수를 근사함)
1. Chain Rule

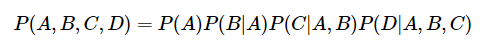
- joint probability를 conditional probability로 펼친 것이다.

2. 문장에 대한 확률

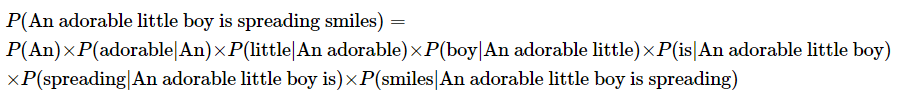
이전 까지의 단어가 주어졌을 때, 다음 단어를 예측하는 확률을 차례대로 곱한 것과 같다.

이전 문장에 다음 단어가 등장할 확률식을 추가시켜 그것을 최대화 할 수 있는 값을 찾아내야 한다.
3. Using Language Model
- 여러개의 문장이 주어졌을 때 가장 알맞은 문장을 고를 수 있다.
- 단어들이 주어졌을 때 다음 단어를 예측할 수 있다. (확률 분포 중 가장 큰 최대값을 찾는 수식을 통해)
언어모델링은 주어진 단어가 있을 때, 다음 단어의 likelihood를 최대화하는 파라미터를 찾는 과정이라고 볼 수 있다.
4. 카운트 기반의 접근

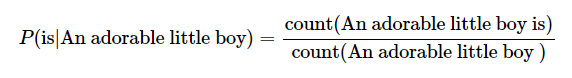
예를 들어 기계가 학습한 코퍼스 데이터에서 An adorable little boy가 100번 등장했는데
그 다음에 is가 등장한 경우가 30번이라면 P(is|An adorable little boy)는 30%가 된다.
4-1. 카운트 기반의 접근의 문제 - 단어 시퀀스가 없는 경우
- 기계가 훈련한 코퍼스에 An adorable little boy is라는 단어 시퀀스가 없었다면 이 단어 시퀀스에 대한 확률은 0이 된다.
- 또는 An adorable little boy라는 단어 시퀀스가 없었다면 분모가 0이 되어 확률은 정의되지 않는다.
- 충분한 데이터를 관측하지 못하여 언어를 정확히 모델링하지 못하는 문제인 희소 문제(sparsity problem)가 발생한다.
- 이를 해결하기 위해 n-gram, 스무딩이나 백오프와 같은 여러가지 일반화(generalization) 기법 등이 있다.
N-gram
- 이전에 등장한 모든 단어를 고려하는 것이 아니라 일부 단어만 고려하는 접근 방법이다.
- 이때 일부 단어를 몇 개 보느냐를 결정하는데 이것이 n-gram에서의 n이 가지는 의미이다.
- n-gram을 사용할 때는 n이 1일 때는 유니그램(unigram),
2일 때는 바이그램(bigram),
3일 때는 트라이그램(trigram)
n이 4 이상일 때는 gram 앞에 그대로 숫자를 붙여서 명명한다.
- n이 커질수록 확률이 정확하게 표현되는데 어려움이 있다.(적절한 n 사용)
- 보통은 3-gram을 사용한다.
- corpus의 양이 많을 때, 4-gram을 사용하기도 한다.
Smoothing
- Markov assumption을 도입하였지만 여전히 문제가 남아있음
- Training corpus에 없는 unseen word sequence의 확률은 0이 되버린다.
- 즉, Smoothing과 Discounting은 Unseen word sequence에 대한 대처를 할 수 있는 방법이다.

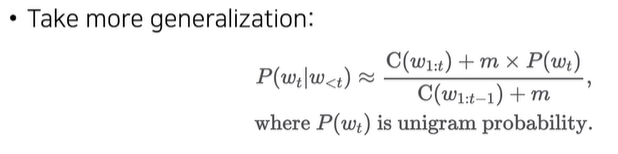
분자 혹은 분모가 0인 경우를 피하기 위해, +m x P(wt)를 하거나 +m를 한다.
Interpolation and Back-off
1. Interpolation
- 다른 Language Model을 linear하게 일정 비율로 섞는 것을 말한다.
- general domain LM + domain specific LM = general domain에서 잘 동작하는 domain adapted LM
- 예를 들어, 의료/법률/특허 등에서 사용

2. Back-off
- 희소성에 대처하는 방법이다.
- 확률 값이 0이 되는 현상은 방지할 수 있다.
- But, unseen word sequence를 위해 back-off를 거치는 순간 확률 값이 매우 낮아져 버린다.
- 음성인식(ASR) 등의 활용에서 어려움이 있다.

Perplexity(PPL)
- 모델 내에서 자신의 성능을 수치화하여 결과를 내놓는 내부 평가(Intrinsic evaluation)에 해당한다.
- 펄플렉서티(perplexity)는 언어 모델을 평가하기 위한 내부 평가 지표이다.
- 테스트 문장에 대해서 언어모델을 이용하여 확률을 구하고 PPL 수식에 넣어 언어모델의 성능을 측정한다.
- PPL은 단어의 수로 정규화(normalization) 된 테스트 데이터에 대한 확률의 역수이다.
- PPL을 최소화한다는 것은 문장의 확률을 최대화하는 것과 같다.
- '낮을수록' 언어 모델의 성능이 좋다는 것을 의미한다.

'Study > AI' 카테고리의 다른 글
| [머신러닝/딥러닝] Language Modeling 2(언어 모델) (0) | 2021.10.11 |
|---|---|
| [머신러닝/딥러닝] 이미지 어그멘테이션 (Image Augmentation) (0) | 2021.08.03 |
| [머신러닝/딥러닝] GAN 요약 정리 (0) | 2021.07.13 |
| [머신러닝/딥러닝] 풀링 계층 (Pooling Layer , CNN) (0) | 2021.05.17 |
| [머신러닝/딥러닝] 합성곱 신경망(Convolutional Neural Network , CNN) (0) | 2021.05.17 |



